
The Mezmo blog
The journey to production AI: Five steps for SRE and platform teams
The journey to production AI: Five steps for SRE and platform teams

The runbook problem: How AURA documents what teams don’t have time to write
The runbook problem: How AURA documents what teams don’t have time to write

AURA in practice: real-world use cases for production AI agent infrastructure
AURA in practice: real-world use cases for production AI agent infrastructure

Why we open-sourced AURA: Infrastructure for production AI
Why we open-sourced AURA: Infrastructure for production AI

The Grok-to-AI evolution: Why modern SREs are moving beyond manual parsing
The Grok-to-AI evolution: Why modern SREs are moving beyond manual parsing

Take back control of your observability spend
Take back control of your observability spend

AI SRE update: Your feedback shaped our latest release
AI SRE update: Your feedback shaped our latest release
.png)
Simplify the collection layer and move to OTel without the agent sprawl
Simplify the collection layer and move to OTel without the agent sprawl

New year, new telemetry: Resolve to stop breaking dashboards
New year, new telemetry: Resolve to stop breaking dashboards

The Observability stack is collapsing: Why context-first data is the only path to AI-powered root cause analysis
The Observability stack is collapsing: Why context-first data is the only path to AI-powered root cause analysis
.jpg)
Mezmo + Catchpoint deliver observability SREs can rely on
Mezmo + Catchpoint deliver observability SREs can rely on

Mezmo’s AI-powered site reliability engineering (SRE) agent for root cause analysis (RCA)
Mezmo’s AI-powered site reliability engineering (SRE) agent for root cause analysis (RCA)
What is Active Telemetry
What is Active Telemetry
Launching an agentic SRE for root cause analysis
Launching an agentic SRE for root cause analysis

Paving the way for a new era: Mezmo's Active Telemetry
Paving the way for a new era: Mezmo's Active Telemetry

The answer to SRE agent failures: Context Engineering
The answer to SRE agent failures: Context Engineering

Empowering an MCP server with a telemetry pipeline
Empowering an MCP server with a telemetry pipeline

The debugging bottleneck: A manual log-sifting expedition
The debugging bottleneck: A manual log-sifting expedition

The smartest member of your developer ecosystem: Introducing the Mezmo MCP server
The smartest member of your developer ecosystem: Introducing the Mezmo MCP server

Your new AI assistant for a smarter workflow
Your new AI assistant for a smarter workflow
The observability problem isn't data volume anymore—It's Context
The observability problem isn't data volume anymore—It's Context
Beyond the pipeline: Data isn't oil, it's power
Beyond the pipeline: Data isn't oil, it's power

The platform engineer's playbook: Mastering OpenTelemetry & compliance with Mezmo and Dynatrace
The platform engineer's playbook: Mastering OpenTelemetry & compliance with Mezmo and Dynatrace
.png)
From alert to answer in seconds: Accelerating incident response in Dynatrace
From alert to answer in seconds: Accelerating incident response in Dynatrace

Taming Your Dynatrace bill: How to cut observability costs, not visibility
Taming Your Dynatrace bill: How to cut observability costs, not visibility

Architecting for value: A playbook for sustainable observability
Architecting for value: A playbook for sustainable observability

How to cut observability costs with synthetic monitoring and responsive pipelines
How to cut observability costs with synthetic monitoring and responsive pipelines

Unlock deeper insights: Introducing GitLab event integration with Mezmo
Unlock deeper insights: Introducing GitLab event integration with Mezmo

Introducing the new Mezmo product homepage
Introducing the new Mezmo product homepage
The inconvenient truth about AI ethics in observability
The inconvenient truth about AI ethics in observability

Observability's Moneyball moment: How AI is changing the game (not ending it)
Observability's Moneyball moment: How AI is changing the game (not ending it)

Do you Grok it?
Do you Grok it?

Top five reasons telemetry pipelines should be on every engineer’s radar
Top five reasons telemetry pipelines should be on every engineer’s radar

Is it a cup or a pot? Helping you pinpoint the problem—and sleep through the night
Is it a cup or a pot? Helping you pinpoint the problem—and sleep through the night

Smarter telemetry pipelines: Control costs, reduce noise, and get ready for agentic operations
Smarter telemetry pipelines: Control costs, reduce noise, and get ready for agentic operations

Telemetry for modern apps: Reducing MTTR with smarter signals
Telemetry for modern apps: Reducing MTTR with smarter signals

Transforming observability: Simpler, smarter, and more affordable data control
Transforming observability: Simpler, smarter, and more affordable data control

Mezmo Recognized with 25 G2 Awards for Spring 2025
Mezmo Recognized with 25 G2 Awards for Spring 2025

Reducing Telemetry Toil with Rapid Pipelining
Reducing Telemetry Toil with Rapid Pipelining

Cut Costs, Not Insights: A Practical Guide to Telemetry Data Optimization
Cut Costs, Not Insights: A Practical Guide to Telemetry Data Optimization

Webinar Recap: Telemetry Pipeline 101
Webinar Recap: Telemetry Pipeline 101

My Favorite Observability and DevOps Articles of 2024
My Favorite Observability and DevOps Articles of 2024

How Mezmo Uses a Telemetry Pipeline to Handle Metrics, Part II
How Mezmo Uses a Telemetry Pipeline to Handle Metrics, Part II

Webinar Recap: 2024 DORA Report: Accelerate State of DevOps
Webinar Recap: 2024 DORA Report: Accelerate State of DevOps

Announcing Mezmo Flow: Build a Telemetry Pipeline in 15 minutes
Announcing Mezmo Flow: Build a Telemetry Pipeline in 15 minutes

Key Takeaways from the 2024 DORA Report
Key Takeaways from the 2024 DORA Report

Webinar Recap | Telemetry Data Management: Tales from the Trenches
Webinar Recap | Telemetry Data Management: Tales from the Trenches

What are SLOs/SLIs/SLAs?
What are SLOs/SLIs/SLAs?

Webinar Recap | Next Gen Log Management: Maximize Log Value with Telemetry Pipelines
Webinar Recap | Next Gen Log Management: Maximize Log Value with Telemetry Pipelines

Creating Re-Usable Components for Telemetry Pipelines
Creating Re-Usable Components for Telemetry Pipelines

Optimizing Data for Service Management Objective Monitoring
Optimizing Data for Service Management Objective Monitoring

More Value From Your Logs: Next Generation Log Management from Mezmo
More Value From Your Logs: Next Generation Log Management from Mezmo

Dogfooding at Mezmo: How we used telemetry pipeline to reduce data volume
Dogfooding at Mezmo: How we used telemetry pipeline to reduce data volume

Unlocking Business Insights with Telemetry Pipelines
Unlocking Business Insights with Telemetry Pipelines

Why Your Telemetry (Observability) Pipelines Need to be Responsive
Why Your Telemetry (Observability) Pipelines Need to be Responsive

Data Optimization Technique: Route Data to Specialized Processing Chains
Data Optimization Technique: Route Data to Specialized Processing Chains

Data Privacy Takeaways from Gartner Security & Risk Summit
Data Privacy Takeaways from Gartner Security & Risk Summit

Mastering Telemetry Pipelines: Driving Compliance and Data Optimization
Mastering Telemetry Pipelines: Driving Compliance and Data Optimization

A Recap of Gartner Security and Risk Summit: GenAI, Augmented Cybersecurity, Burnout
A Recap of Gartner Security and Risk Summit: GenAI, Augmented Cybersecurity, Burnout

Why Telemetry Pipelines Should Be A Part Of Your Compliance Strategy
Why Telemetry Pipelines Should Be A Part Of Your Compliance Strategy

Pipeline Module: Event to Metric
Pipeline Module: Event to Metric

Telemetry Data Compliance Module
Telemetry Data Compliance Module

OpenTelemetry: The Key To Unified Telemetry Data
OpenTelemetry: The Key To Unified Telemetry Data

Data optimization technique: convert events to metrics
Data optimization technique: convert events to metrics
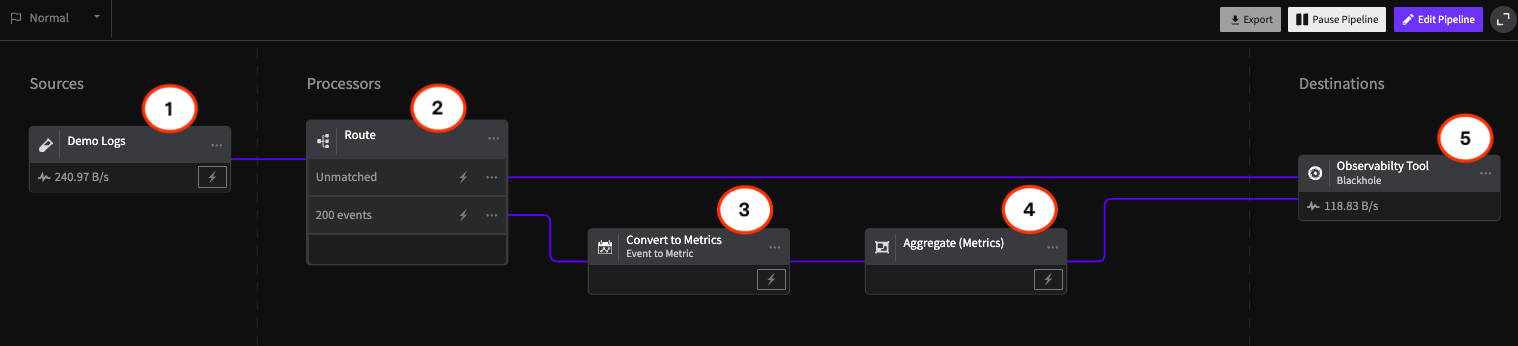
What’s New With Mezmo: In-stream Alerting
What’s New With Mezmo: In-stream Alerting

How Mezmo Used Telemetry Pipeline to Handle Metrics
How Mezmo Used Telemetry Pipeline to Handle Metrics

Webinar Recap: Mastering Telemetry Pipelines - A DevOps Lifecycle Approach to Data Management
Webinar Recap: Mastering Telemetry Pipelines - A DevOps Lifecycle Approach to Data Management

Open-source Telemetry Pipelines: An Overview
Open-source Telemetry Pipelines: An Overview

SRECon Recap: Product Reliability, Burn Out, and more
SRECon Recap: Product Reliability, Burn Out, and more

Webinar Recap: How to Manage Telemetry Data with Confidence
Webinar Recap: How to Manage Telemetry Data with Confidence

Webinar Recap: Myths and Realities in Telemetry Data Handling
Webinar Recap: Myths and Realities in Telemetry Data Handling

Using Vector to Build a Telemetry Pipeline Solution
Using Vector to Build a Telemetry Pipeline Solution

Managing Telemetry Data Overflow in Kubernetes with Resource Quotas and Limits
Managing Telemetry Data Overflow in Kubernetes with Resource Quotas and Limits

How To Optimize Telemetry Pipelines For Better Observability and Security
How To Optimize Telemetry Pipelines For Better Observability and Security

Gartner IOCS Conference Recap: Monitoring and Observing Environments with Telemetry Pipelines
Gartner IOCS Conference Recap: Monitoring and Observing Environments with Telemetry Pipelines

Webinar Recap: Best Practices for Observability Pipelines
Webinar Recap: Best Practices for Observability Pipelines

Introducing Responsive Pipelines from Mezmo
Introducing Responsive Pipelines from Mezmo

My First KubeCon - Tales of the K8’s community, DE&I, sustainability, and OTel
My First KubeCon - Tales of the K8’s community, DE&I, sustainability, and OTel

Modernize Telemetry Pipeline Management with Mezmo Pipeline as Code
Modernize Telemetry Pipeline Management with Mezmo Pipeline as Code

Kubernetes Telemetry Data Optimization in Five Steps with Mezmo
Kubernetes Telemetry Data Optimization in Five Steps with Mezmo

Introducing Mezmo Edge: A Secure Approach To Telemetry Data
Introducing Mezmo Edge: A Secure Approach To Telemetry Data

Understand Kubernetes Telemetry Data Immediately With Mezmo’s Welcome Pipeline
Understand Kubernetes Telemetry Data Immediately With Mezmo’s Welcome Pipeline

Unearthing Gold: Deriving Metrics from Logs with Mezmo Telemetry Pipeline
Unearthing Gold: Deriving Metrics from Logs with Mezmo Telemetry Pipeline
Webinar Recap: The Single Pane of Glass Myth
Webinar Recap: The Single Pane of Glass Myth
Empower Observability Engineers: Enhance Engineering With Mezmo
Empower Observability Engineers: Enhance Engineering With Mezmo

Webinar Recap: How to Get More Out of Your Log Data
Webinar Recap: How to Get More Out of Your Log Data
Unraveling the Log Data Explosion: New Market Research Shows Trends and Challenges
Unraveling the Log Data Explosion: New Market Research Shows Trends and Challenges
Webinar Recap: Unlocking the Full Value of Telemetry Data
Webinar Recap: Unlocking the Full Value of Telemetry Data
Data-Driven Decision Making: Leveraging Metrics and Logs-to-Metrics Processors
Data-Driven Decision Making: Leveraging Metrics and Logs-to-Metrics Processors
How To Configure The Mezmo Telemetry Pipeline
How To Configure The Mezmo Telemetry Pipeline
Supercharge Elasticsearch Observability With Telemetry Pipelines
Supercharge Elasticsearch Observability With Telemetry Pipelines
Enhancing Grafana Observability With Telemetry Pipelines
Enhancing Grafana Observability With Telemetry Pipelines
Optimizing Your Splunk Experience with Telemetry Pipelines
Optimizing Your Splunk Experience with Telemetry Pipelines
Webinar Recap: Unlocking Business Performance with Telemetry Data
Webinar Recap: Unlocking Business Performance with Telemetry Data
Transforming Your Data With Telemetry Pipelines
Transforming Your Data With Telemetry Pipelines
6 Steps to Implementing a Telemetry Pipeline
6 Steps to Implementing a Telemetry Pipeline
Webinar Recap: Taming Data Complexity at Scale
Webinar Recap: Taming Data Complexity at Scale
Webinar Recap: Observability Data Orchestration
Webinar Recap: Observability Data Orchestration
Deciding Whether to Buy or Build an Observability Pipeline
Deciding Whether to Buy or Build an Observability Pipeline
Why Culture and Architecture Matter with Data, Part I
Why Culture and Architecture Matter with Data, Part I
Ready to transform your observability?
Experience the power of Active Telemetry and see how real-time, intelligent observability can accelerate dev cycles while reducing costs and complexity.
- ✔ Start free trial in minutes
- ✔ No credit card required
- ✔ Quick setup and integration
- ✔ Expert onboarding support
