Datadog: The Good, The Bad, The Costly
When things break, logs are often the first place you turn to figure out what's going on, which is why Datadog makes it easy to find them. The ability to pivot between traces, metrics, and logs in one place speeds up investigations and helps teams move faster during incidents. That level of correlation is a big reason so many teams rely on Datadog.
The biggest downside? Cost scales with data ingestion, not value. Datadog charges for every log sent, regardless of whether it’s ever queried—and most teams send a lot of logs. It's easy to ingest gigabytes of data a day without even trying between verbose debug lines, structured logs from microservices, and high-frequency infrastructure logs. As the number of data sources grows at a rate of 32% a year, teams that fail to strategically manage log volume will find that costs will quickly outpace value. This problem worsens when volume spikes during deploys, outages, or traffic surges, which can unexpectedly rack up tens of thousands of dollars in overages.
Controlling Logging Costs
It’s easy to fall into the trap of keeping everything. For decades, developers have been told to save every log just in case it is needed during an incident. This fear often outweighs concerns about cost. But not all logs deliver the same value. Some are essential for investigations or audits. Others are redundant, low-signal, or never queried at all. The longer everything gets ingested without scrutiny, the harder it becomes to separate what’s useful from what’s just adding cost without adding value.
Bringing costs under control starts with breaking the habit of data hoarding. That means understanding which logs serve a purpose, when they’re needed, and which ones don’t (or rarely) serve a purpose, and then putting systems in place to treat them differently.
What Datadog Offers Today and Where It Falls Short
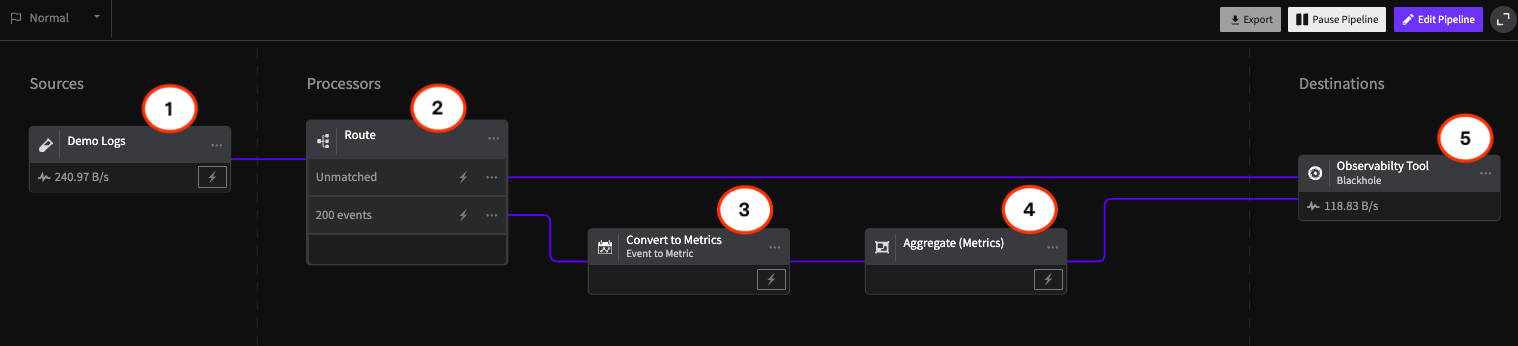
Datadog provides limited tooling to help manage log volume. It has exclusion filters, which let you drop logs before indexing, and indexing controls, which let you decide what gets stored, archived, and ignored. These features help teams cut out obvious noise like heartbeat checks, verbose debug lines, or infrequent logs with no operational value, but there's a catch: you’re forced to keep the log and pay full price, or drop it entirely and lose all its value.
Datadog provides limited flexibility once logs are ingested. There’s no way to aggregate noisy, repetitive logs or apply more fine-tuned control as you’re locked into their query language. While features like log-based metrics and rehydration exist, they keep you locked into Datadog’s ecosystem and costs. For SREs trying to optimize observability without losing signal, these constraints make meaningful control harder than it should be.
When Is It Time to Consider Telemetry Pipelines?
While Datadog’s native controls are a reasonable starting point, as log volumes increase and cost pressures mount, the need for more flexibility becomes difficult to ignore. That’s why many developers and SREs responsible for logging are leveraging telemetry pipelines to get fine-grained control of their data.
A telemetry pipeline allows you to shape, filter, and route that data before it reaches your observability tools. Instead of being constrained by vendor-specific options, you define what matters, how it should be handled, and where it should go. A good pipeline service will even help you understand your log content and give guidance on what actions you should take.
This approach helps reduce costs without sacrificing operational value. High-volume logs can be aggregated by collapsing repetitive entries and preserving a single version with contextual metadata. Logs can be converted into event metrics to track trends without storing raw data. You can send logs to multiple destinations, use lower-cost storage for less critical data, or adopt new tools without being locked into a single vendor ecosystem.
If you have reached the limits of exclusion filters and indexing rules, or if your team is spending more time on cost management than observability, consider telemetry pipelines. They are not just a cost-saving measure but a strategic layer for gaining long-term control over your data. Scale your observability with the tools you love without scaling costs.
Table of Contents
Share Article


RSS Feed





.png)


.jpg)








.png)























.png)