

RELATED Lessons
SHARE ARTICLE
How to Use S3 Access Logs
Learning Objectives
• Learn how to obtain S3 Access logs
• Learn how to make S3 Access logs readable for analysis
Amazon Simple Storage Service, aka S3, is one of the most popular and user-friendly services on AWS. S3 allows any file storage, providing scalability while avoiding performance and security problems. It is worth mentioning that many resources are available that would enable the use of S3 in different ways, such as versioning, website hosting, and logs for access auditing. This tutorial will show you how to use S3 access logs via code.

AWS S3 Access Log Content
AWS S3 provides log information regarding access to buckets and their objects. AWS S3 logs record the following: bucket owner, bucket, time, remote IP, requester, operation, request ID, requestURI, key, error code, bytes sent, HTTP status, total time, object size, turnaround time, user agent, referrer, host ID, version ID, cipher suite, signature version, authentication type, TLS version, and host header.
When access to an object is requested, users can use this information to identify the origin of the requester. You can check if unauthorized agents have accessed any resources or identify a resource with an unusually high number of downloads. You can also determine whether the turnaround time for receiving a file is within the expectations of applications and users. In addition, this information can help you understand how an application has been used by showing the resource and version that has a request pending.
We will show you how to obtain these logs and make them readable for analysis in the following sections.
Enabling Logging for Bucket Objects
To use S3 logs, you first need to create one bucket to store files (objects) and another to store the logs. This should be created in the same region. It is a good practice not to save the logs in the same bucket because we want to save the logs for the interactions that the bucket receives and if the bucket has a problem the logs may not be able to be saved with the information about what is causing the error.

After you’ve created the buckets, go to the Properties of the bucket that will store the files to associate it with the bucket for logs. On the Properties page, click on the Edit button in the Server access logging box. In this form, select Enable to allow the bucket to provide log data about stored objects, then click on Browse S3 to select the log bucket.
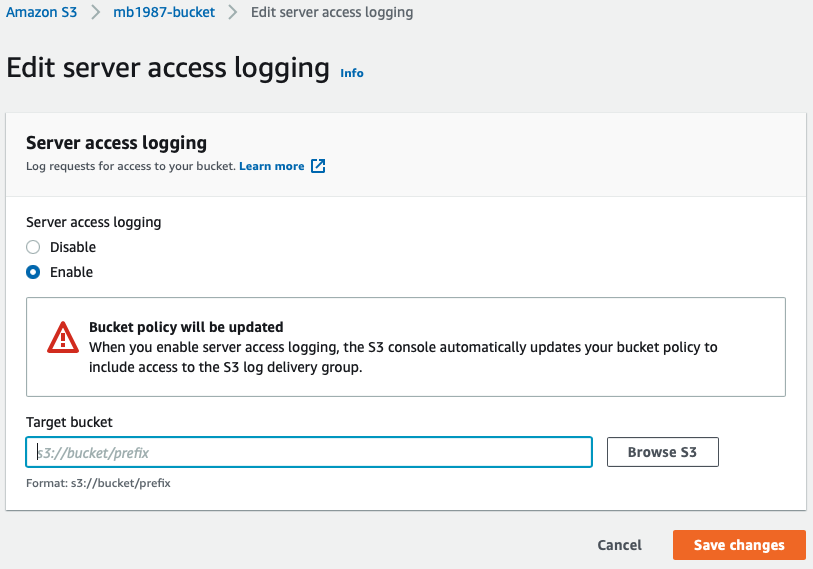
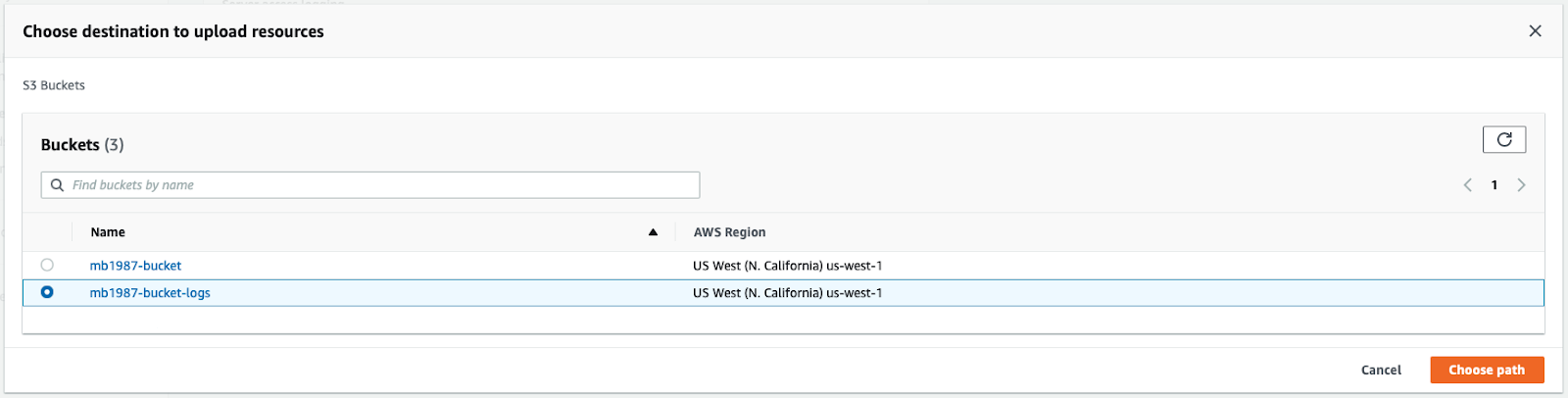
In the modal, select the proper bucket and click on Choose path. Back in the form, click on Save changes to apply the association between the buckets. Clicking that button is all you need to do to start saving object usage logs.
Testing Logging
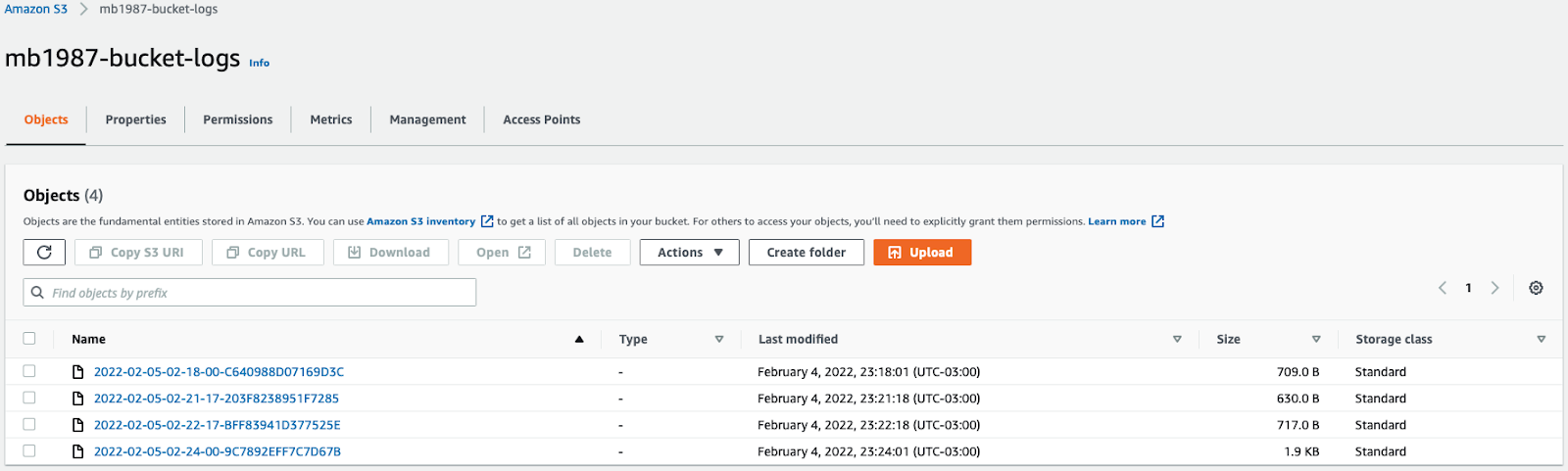
Now, let’s try to access the bucket and upload some files. For this test, there is no need to add any other settings. You can open, download, and remove files to generate logs for these actions. Then, you can access the bucket for logs and wait a few minutes to receive the log data about the newly uploaded file. Then, open the logs to see the type of data available in the log information. You will see logs related to actions taken within the bucket to get or remove objects, along with policies and versioning information.
Log Data Samples
Let’s take a look at some sample logs and their available formats on AWS S3. For example, this is delete:
And this is get:
Download Logs
To implement an S3 log reader, you first need to download the logs locally. AWS SDK S3 provides a few methods for getting S3 objects programmatically. For this reader, we will use AWS SDK for Ruby.
AWS SDK S3 for Ruby can be installed via gem:
Once you have it installed, you can either use IRB code or run Ruby code. Choose your preferred method, and don't forget to get your credentials from IAM. You will need an access key ID and a secret access key. Now, create a new folder called logs to store the logs locally.
Now, all logs will be stored locally inside the logs folder.
Exporting S3 Access Logs to JSON
Unfortunately, AWS S3 does not provide the logs in JSON format. In order to read them, you must implement a job to wrap the logs within the organized structure.
The following code will read each downloaded log, select key, remote IP, and operation storing in a list that will be exported as a JSON file.
Conclusion
Reading AWS S3 logs on your own is possible, but it may not be practical or very effective. That’s because you need to retrieve the logs and make them readable before you can get insights into the access info. AWS provides services that facilitate the use of S3 logs. For example, Amazon Athena enables you to create a database to store your S3 logs and query the data easily. You could also integrate AWS CloudTrail with S3 or use a data monitoring solution like Mezmo, formerly LogDNA. As a developer, it’s always good to know about different ways to use logs and how they can help you.
It’s time to let data charge

.svg)




